

What common denominator does the following web security risks all have in common?
- Cross-site Scripting (XSS)
- SQL / Injection Attacks
- Missing Function Level Access Controls
- Unvalidated Redirects and Forwards
Untrusted data plays a vital rule in the success of exploiting an application through one of these types of vulnerabilities. It won’t take long when mitigating the immense list of web security risks to see that there is one particular common denominator; untrusted data. However, like a needle in a haystack, it’s one thing to know its there, and another to know how to find it.
Identifying Untrusted Data
It’s very easy to assume you know how to identify untrusted data. For the most part, it’s definitely any information that someone submits to your application right? Or is it? I’m going to ask you a few questions and see how you fair when it comes to determining if certain information should be trusted or not.
|
Hopefully, you said untrusted. This is probably the easiest to identify and the most predicted way of injected untrusted data into an application.
 |
|
This starts to get a bit more tricky. It’s easy to believe that because this type of information is being provided on the HTTP request by the agent such as a browser, we can trust it. But in reality, request headers can be augmented to whatever the requestor wants it to be, whether factitious or true.
|
At face value, information provided in a hidden field can’t be trusted. Even if you are providing it yourself and it’s originating server-side. This is directly related to the trust border which we’ll be talking about shortly.
|
The database is in your control, it sits behind your firewall, what isn’t there to trust? The truth is, it can’t be fully trusted. When you toss in the ability for external sources such as a user, the ability save arbitrary information as in profile information, preferences, images and comments to the database or the insider threat such as a rogue database administrator who can provide unexpected information in a database, its easy to see how the database, once believed to be complete safe, might not be so safe after all.
So, if you answered “trusted” to any of these questions, chances are, maybe you aren’t as sure about what can or can’t be trusted.
How Can We Identify Untrusted Data?
To answer that question, I am going to give you a 3 rules to help you identify what is untrusted data.
Rule #1
This is the most obvious and straight forward rule and you can apply this rule simply by asking the question:
“Where did this information come from?”
This is the broadest approach that can cover the most obvious cases. But asking this question we can help identify data that might be right under our nose, yet easily missed.
 For example, application frameworks are handling more and more of the heavy lifting and mundane actions. Browsers and client frameworks can facilitate constructing the HTTP request that our backend web servers are listening for. Therefore, its common place for developers to fall into notion that the HTTP request is safe because they didn’t have to construct it in their client application. A perfect, out of sight, out of mind scenario.
For example, application frameworks are handling more and more of the heavy lifting and mundane actions. Browsers and client frameworks can facilitate constructing the HTTP request that our backend web servers are listening for. Therefore, its common place for developers to fall into notion that the HTTP request is safe because they didn’t have to construct it in their client application. A perfect, out of sight, out of mind scenario.
But in reality, HTTP headers can contain information such as user-agent, ip address, mime type – metadata about the information in the request and be dictated by the requestor. Therefore, this brings us to our second rule.
Rule #2
A trust boundary defines what within that boundary can actually be trusted. For a web application, a very small area can be viewed as a trust boundary such as immediate resources tied to our web server. Resources such as configuration files, and possibly static files stored locally, as a couple examples of trusted resources.
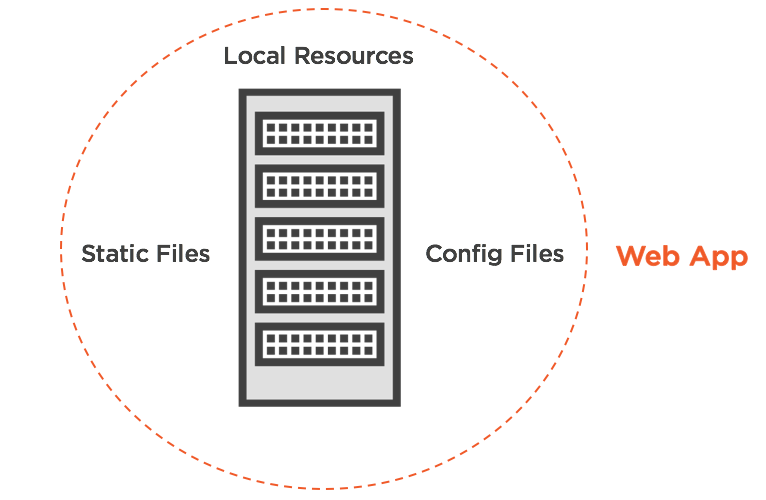
In this day and age of dynamic, user-driven web applications, the idea solution of serving up only static data is not realistic. Therefore, we can consider any resource outside our immediate control as untrusted. Resources such as HTTP requests, and even external services or API’s that we acquire information from.
To help evaluate this rule we can ask the question:
“What path has this data traveled?”
Going back to one of our previously mentioned questions, even though the value of a hidden field is generated server side, because it crosses a trust boundary, it can’t be trusted face value. It requires additional validation to maintain its integrity through the use of encryption or message authentication code. This way, even though the data crosses a trust boundary, it can be validated to be authentic.
Finally, when discussing the integrity of the data, we can’t leave out the last rule.
Rule #3
I would be short changing you if I didn’t include a major component and reason for a number of security breaches we see today – the insider threat. With this rule we’re encompassing both the human element such as DBA as well as internal resources like web services that interact with your database or similar critical key areas of your application.
Now, I’m not running around perpetuating that database administrators are out to sabotage your application, but it would behoove you to be aware of all the chefs in the kitchen. The insider threat is not an edge-case, its an everyday-case.

In 2013, Target was the victim of a data breach. Believed to be the result of a compromised trusted 3rd party security vendor.
A large percentage of data breaches are carried out through two prominent methods, social engineering and email based phishing attacks. Either shares a common denominator of the victim being an insider to the company being attacked. In these cases, the insider happens to unintentionally be the weakest security link, and threat to the company.
We can evaluate this rule by asking the question:
“Who has access to the data, and should they?
There are a number of macro approaches to addressing the insider threat. Two significant ways to reduce the chance of insider threats are:
Principle of least privilege; ensuring that insider resources have only the minimal access to key areas that are needed for them to carry out their tasks. This is also a pillar of web application security practices that developers must adhere to in order to mitigate a number of risks as well.
Security Training; When it comes to application security, there are risks we don’t know we don’t know, which are commonly referred to as unknown unknowns. But, there are threats that we can deal with because we known how to deal with them. Providing the proper security training are going to be key when it comes to addressing the insider threat and also the bases for companies like KnownB4 who provide professional security training for company employees.
Conclusion
Understanding the significance of untrusted data and how it relates to your application is a crucial step in getting the jump on mitigating a vast number of web application security risks. When you’re working with data within your application you can help direct where and how your mitigations are applied and shore up holes in your application by doing these 3 steps:
- Applying these 3 rules
- Asking the associated question for those rules
- Making no assumptions about the data.
Knowing how to identify untrusted data is the first step. This will lead to the next part that we’ll look at examples of how to exactly handle untrusted data in your application.